
Ich gebe es offen zu: Ich gehöre zu den „altbackenen“ Meteorologen, die großen Wert auf Textprognosen legen. Warum? In ausformulierten Wetterberichten kann man eigene Erfahrungen besser einbringen und Unsicherheiten und Gefahren ausdrücken, etwa zum Gewitterrisiko oder der Gefahr starker Föhnstürme. Wenn ein Modell bei Südföhn 40 km/h Spitzen ausgibt, können es in prädestinierten Tallagen oder besonders anfälligen Gipfeln durchaus 80 oder 100 km/h Spitzen sein, was ich textlich entsprechend abfangen kann.
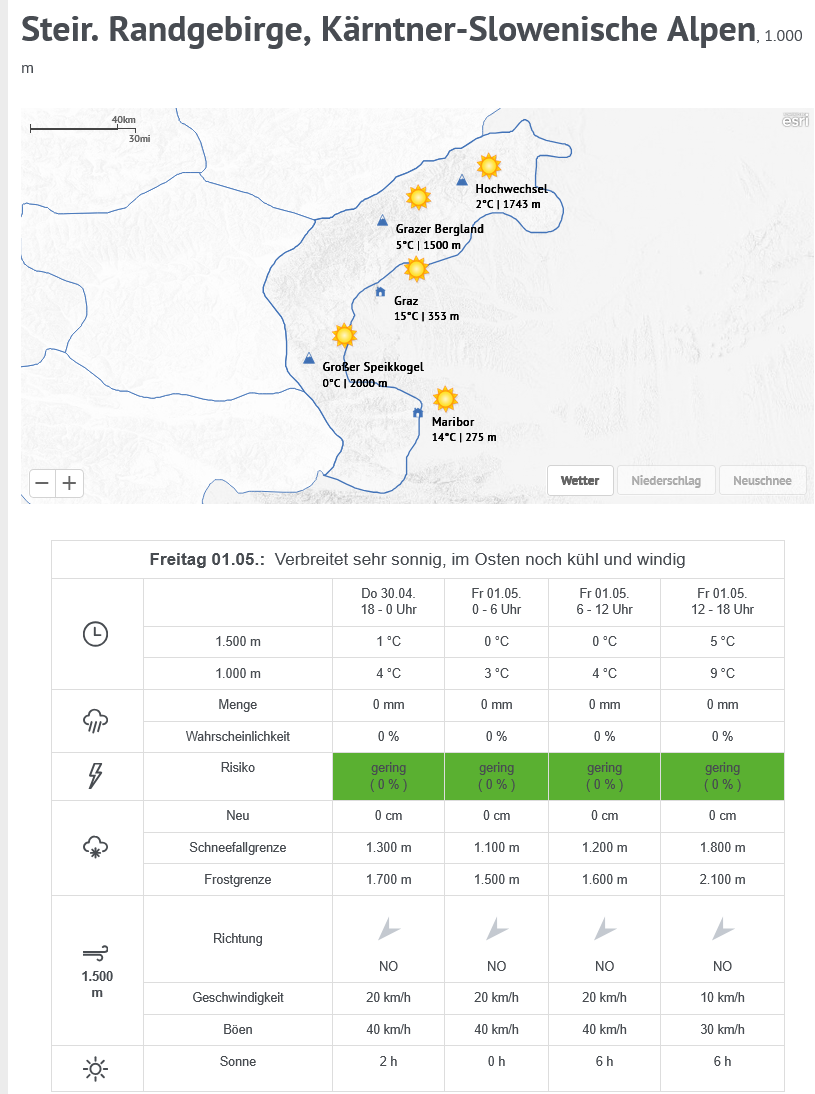
Die bereits erfolgte Neuerung (siehe auch diese Meldung hier) suggeriert eine Genauigkeit mit „0 oder 1“, die so nicht haltbar ist, da es sich um sogenannten „direct modeloutput“ handelt – um Gitterpunkte eines Modells, wo für Orte dazwischen interpoliert wird. Im Modell ist der Berg aber meist nicht so hoch wie in der Realität und es kommen fiktive Werte heraus, die so nicht eintreffen werden. Der Laie weiß das aber nicht. Er weiß auch nicht, was 30 oder 50% Gewitterwahrscheinlichkeit bedeuten. Gewittert es dann ein Drittel oder die Hälfte des Tages? Bedeutet 30% Gewitterwahrscheinlichkeit „unwahrscheinlich“? Oder liegt das simulierte Radarecho vielleicht knapp am Rande des Gitterpunkts, während 10km weiter ein Volltreffer zu erwarten ist – dort aber unglücklicherweise die Tour stattfindet?
Es ist längst keine Neuigkeit mehr, dass die Lese- und Schreibkompetenz durch Digitalisierung, Social Media und KI-Einsatz leidet. Es erschließt sich mir bis heute nicht, warum Meteorologinnen und Meteorologen an ihrer eigenen Abschaffung mitarbeiten. Warum beschleunigen wir diese fatale Entwicklung?
Weiterlesen